원글 페이지 : 바로가기
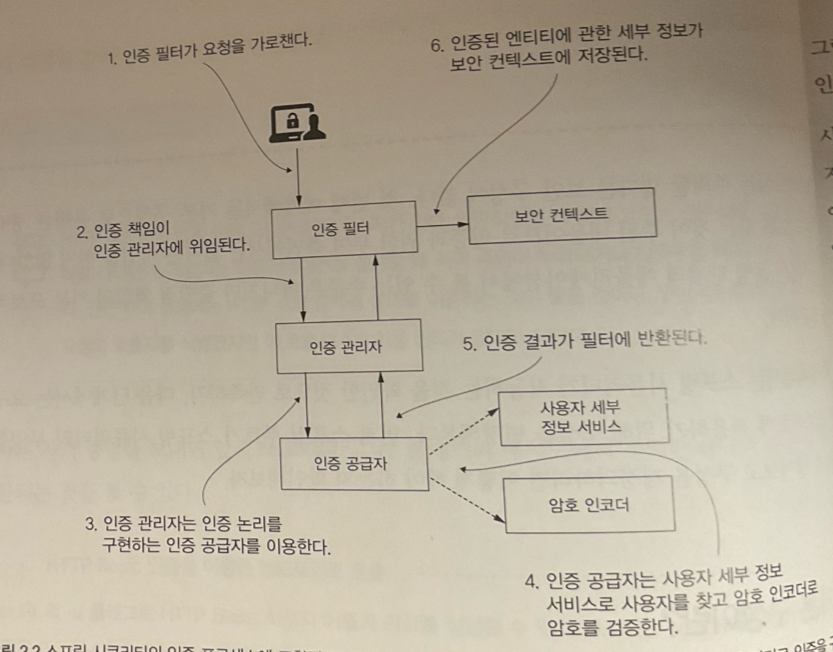
이번 스프린트 기간동안 개발한 나의 작업 카카오, 구글 로그인 ( 구글은 보완 필요 ) 로그아웃, 회원 탈퇴 일기 상세 페이지 API 즐겨찾기, 화가 , 감정 API 카프카 배포 소나큐브를 통한 코드품질 확인 카카오 , 구글 로그인 With Spring Security Spring Security 를 적용하기 위해 Spring Security in Action 책을 읽고 개발을 하였다! 하지만 해당 책은 Spring Security 5.x.x 버전으로 현재 내가 개발하고 있는 springboot 3.x.x 버전에는 알맞지 않았다. 스프링 시큐리티의 기본적인 로직은 다음과 같다. spring security in action 인증 필터를 거치고 인증 관리자를 거친후 , authenticatino provider에게 사용자 세부 정보와 암호 인코더를 받아서 인증을 한 이후 해당 유저에 대한 정보를 보안 컨텍스트에 저장한다. 하지만 이번 프로젝트는 애플리케이션 개발이기 때문에 사용자의 보다 쉬운 로그인을 돕기 위해 OAuth 와 JWT를 사용해 로그인을 할 수 있도록 하였다. 인증 로직 이번 개발에서 사용한 로그인의 흐름도는 다음과 같다. 로그인을 요청하면 클라이언트는 sns 계정을 통해 로그인을 한다. 이후 로그인을 하면 제공되는 승인코드를 통해 소셜 계정의 토큰을 발급받는다. 발급 받은 토큰을 토대로 해당 유저의 정보를 가져와 우리의 서비스의 회원에 가입시킨다. 이후 가입된 유저에게 Jwt를 발급한다. 발급한 JWT의 유저정보를 spring security Context 에 넣어 접근가능하게 하도록 한다. 이후 spring security 의 filterchain을 통해 들어오는 통신에 대해 jwt가 올바르다면 앱의 접속을 허가한다. 여기서 filterchain을 JwtAuthenticationFilter를 usernamePasswordAuthenticationFilter 앞에 배치해 필터체인이 적용되도록 하였다. 스프링 시큐리티를 적용하고 나니 문제점 스프링 시큐리티만을 적용하고 나니, 에러가 나면 403 에러로 무조건 빠져버렸다. 스프링 공식 블로그에 따르면, 스프링부트에서는 에러가 발생하면 /error라는 URI로 매핑을 시도한다. 실제로 해당 URI로 이동하면 아래와 같은 페이지가 나타난다. Whitelabel Error Page 자체는 403 에러와 관련이 없지만 에러가 발생하면 /error로 매핑을 시도한다는 것이 핵심이다. 하지만 우리는 /error 엔드포인트에 대해서 허가해주지 않았기 때문에 에러페이지로 이동할 때 토큰이 없어 403 에러가 나버렸던 것이다. 이후 토큰에 대한 에러코드들을 작성한 이후 jwtAuthenticationFilter 앞에 entryPoint에 대한 필터체인에 걸어주었더니 토큰에 대한 에러들도 확인할 수 있었다. Resolver JWT 토큰을 보낼때 마다 해당 토큰에서 유저 id와 role을 꺼내고 싶었다. @Target(ElementType.PARAMETER)
@Retention(RetentionPolicy.RUNTIME)// 런타임동안 유지
@Parameter(hidden = true)// swagger에서 보이지 않게 설정
public @interface AuthUser {
}
다음과 같은 어노테이션 인터페이스를 만들고, @Component
public class AuthUserArgumentResolver implements HandlerMethodArgumentResolver {
public AuthUserArgumentResolver() {
}
@Override
public boolean supportsParameter(MethodParameter parameter) {
return parameter.getParameterType().equals(JwtTokenInfo.class) &&
parameter.hasParameterAnnotation(AuthUser.class); // 지원 파라미터 타입
}
@Override
public Object resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, WebDataBinderFactory binderFactory) {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
Claims claims = (Claims) authentication.getPrincipal();
Long userId = Long.parseLong((String) claims.get(JwtProperties.USER_ID));
UserRole userRole = UserRole.valueOf((String) claims.get(JwtProperties.USER_ROLE));
return JwtTokenInfo.builder()
.userId(userId)
.userRole(userRole)
.build();
}
}
resolver를 사용해 @auth 어노테이션으로 들어오는 jwt에 대해 토큰의 id와 role을 꺼낼 수 있도록 하였다. @Configuration
@RequiredArgsConstructor
public class WebConfig implements WebMvcConfigurer {
private final AuthUserArgumentResolver authUserArgumentResolver;
@Override
public void addArgumentResolvers(List
resolvers.add(authUserArgumentResolver);
}
}
이 resolver를 webMvcConfigure에 추가하여 사용할 수 있도록 하였다. Kafka 설치 ( kafka- kraft 모드 ) 지난 스프린트 까지는 카프카를 로컬에서 돌려서 테스트용으로 사용을 하였다. 이번 스프린트에서 kafka를 설치해 실제 ai 서버와 메세지를 주고받고 하면서 그림일기 생성 로직을 완성하고자 하였다. 기존의 kafka는 zookeeper와 같이 사용하는 툴이었다. 주키퍼는 카프카의 메타정보를 관리해주었다. 하지만 2.7 버전부터 주키퍼의 의존성을 제거하고자 하였고, 3.5.x 버전부터 의존성을 제거한 Kraft 모드를 냈다. 4.x.x 버전부터는 주키퍼의 의존성을 아예 제거한다고 한다. 설치 방법 원래 상용 환경에서는 인스턴스를 여러개 사용하여, 컨트롤러 3개, 브로커 3개를 사용하여 운영하지만, 비용의 문제상으로 하나의 인스턴스에 브로커와 컨트롤러를 둘다 사용하는 3개의 브로커를 사용한다. 포트는 다 다르게 사용했다. 브로커 1 : 9092, 브로커 2 : 9093 , 브로커 3 : 9094 컨트롤러 1: 9095, 컨트롤러 2: 9096, 컨트롤러 3: 9097 java설치 sudo apt update
sudo apt upgrade
sudo apt install openjdk-17-jdk -y kafka ec2에 설치 wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz
tar -xzf kafka_2.13-3.7.1.tgz
sudo mv kafka_2.13-3.7.1 /opt/kafka
mkdir -p /opt/kafka/logs/broker{1,2,3} 카프카를 다운받는다. 압축 해제 카프카 파일을 옮김 카프카 로그를 찍을 디렉토리를 생성한다. 카프카 클러스터 ID 생성 KAFKA_CLUSTER_ID=”$(/opt/kafka/bin/kafka-storage.sh random-uuid)”
echo “KAFKA_CLUSTER_ID: $KAFKA_CLUSTER_ID” 각 브로커에 대한 설정 파일 생성 및 수정 경로 : /opt/kafka/config/kraft 해당 경로에 server1.properties, server2.properties, server3.properties 를 생성한다 # server1.properties
############################# Server Basics #############################
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance’s roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@localhost:9095,2@localhost:9096,3@localhost:9097
############################# Socket Server Settings #############################
# The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092,CONTROLLER://:9095
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for “listeners”.
advertised.listeners=PLAINTEXT://**{ec2의 public IP}**:9092
# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
**log.dirs=/opt/kafka/logs/broker1**
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
**num.partitions=3 # 파티션의 개수를 3개로 하였다.**
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics “__consumer_offsets” and “__transaction_state”
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=24
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
# server2.properties
############################# Server Basics #############################
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance’s roles
node.id=2
# The connect string for the controller quorum
controller.quorum.voters=1@localhost:9095,2@localhost:9096,3@localhost:9097
############################# Socket Server Settings #############################
# The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9093,CONTROLLER://:9096
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for “listeners”.
**advertised.listeners=PLAINTEXT://{ec2의 public IP}:9092**
# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/opt/kafka/logs/broker2
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=3
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics “__consumer_offsets” and “__transaction_state”
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=24
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
다음과 같이 server3.properties에 대해서도 작성해준다. 접속하는 컨트롤러는 9092 포트로만 접속하도록 하였다. 각 브로커의 데이터 디렉토리 초기화 /opt/kafka/bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/config/kraft/server1.properties
/opt/kafka/bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/config/kraft/server2.properties
/opt/kafka/bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/config/kraft/server3.properties 백그라운드로 실행 java 기반의 도구이기 때문에 nohup 을 통해 백그라운드로 실행한다. nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server1.properties > /opt/kafka/logs/broker1.log 2>&1 &
nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server2.properties > /opt/kafka/logs/broker2.log 2>&1 &
nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server3.properties > /opt/kafka/logs/broker3.log 2>&1 & SonarQube 이번 스프린트 마지막쯤 멘토님께서 소나큐브를 통한 코드 품질을 확인해볼 것을 추천하셨다. 소나큐브를 배포한 이후 화면은 다음과 같다. 어떠한 부분에서 문제가 있는지 확인할 수 있어, 다음 스프린트에 리팩토링을 할 예정이다. 또한 작성되어있는 test코드가 있으나 build -x test로 테스트코드를 제외하고 빌드를 해 커버리지가 나오지 않아 이 부분도 수정할 예정이다! 도움받은 블로그들 https://dbfl720.tistory.com/858 https://velog.io/@readnthink/nohup%EC%9C%BC%EB%A1%9C-%EB%B0%B1%EA%B7%B8%EB%9D%BC%EC%9A%B4%EB%93%9C-%EC%8B%A4%ED%96%89%ED%95%98%EA%B8%B0 https://hoing.io/archives/4029 https://velog.io/@enosoup/EC2-On-SonarQube https://velog.io/@_koiil/Ubuntu%EC%97%90-Kafka-%EC%84%9C%EB%B2%84-%EB%B0%B0%ED%8F%AC