원글 페이지 : 바로가기
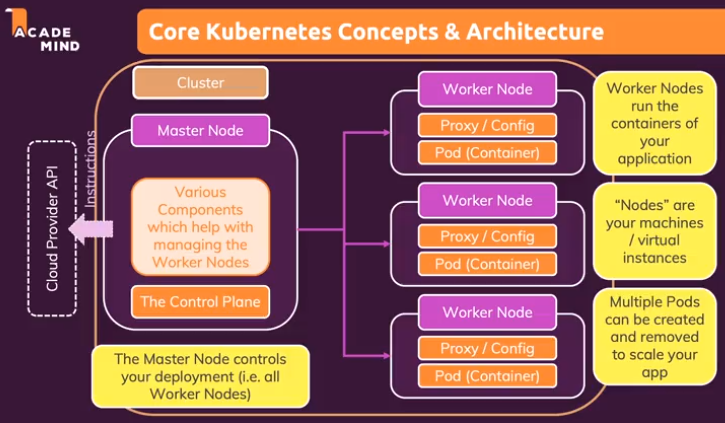
Kubenetes는, 프로그램(애플리케이션)을 Container 로 배포, 확장 및 관리할 때 사용하는 시스템 Docker Container 를 배포하고 orchestration 하는 표준 시스템임 Kube 는 여러 머신을 위한 docker-compose 라고 생각할 수 있음 docker-compose 는 하나의 머신 위에 여러 Container 를 띄우고 관리하고 Kube 는 더 나아가 여러 머신 위에 여러 Container 를 띄우고 모두 관리(배포, 모니터링 등)함 Kube 없이 수동으로 Container 를 배포하면, Container 가 떠야 할 서버를 직접 구성 및 관리해야하며 Container 관리, 즉 보안, 구성, Container 간 충돌, Container down 등의 이슈도 직접 처리해야 함 Container down 이 발생 할 때마다 직접 모니터링하고 이슈를 해결하고 수동으로 재배포해줘야 하는 번거로움이 있음 (근데 이건 Kube 써도 마찬가지 아닌가) Container 로 들어오는 트래픽이 양이 변할 때 Container Scaling 을 수동으로 처리해야 하며 트래픽을 모든 Container 에 고르게 분산시키기 위해 추가 작업을 해야 함 Kube 를 사용하면 자동 배포, Scaling, 로드 밸런싱, Container 관리 등을 손쉽게 할 수 있음 Kube 는 (EC2 처럼 CPU, RAM 이 장착된 Physical/Virtual 머신인) 하나 이상의 Worker Nodes 로 이루어져 있으며 Worker Nodes 는 (실제 Container 와 동일한) 하나 이상의 Pods (=Containers) 와 (Pods 의 네트워크 트래픽 제어를 위한) Proxy/Config 로 이루어져 있음 Prox/Config 는 Pods 가 외부 인터넷에 연결 가능한지 여부와 외부 인터넷에서 (Pods 내부에서 실행되는) Container 로 어떻게 접근할 수 있는지를 제어함 Kube 를 사용하여 Container 및 Pod 를 동적으로 추가/제거하는 경우 Kube 가 사용 가능한 Worker nodes 에 Pods 가 자동으로 배포됨 따라서 서로 다른 여러 Worker Nodes 위에서, 여러 Containers 를 실행하여 워크로드를 고르게 분배 가능함 Worker Nodes 에 Pods 를 새로 띄우거나, (실패하거나 필요하지 않은 경우) Pods 를 교체하거나 종료하는 역할은 Master Node 에 의해 진행됨 Master Node 는 Worker Nodes 처럼 하나의 머신임 Master Node 위에서 실행되는 Control Plane 이 위 작업을 수행하게 됨 Control Plane 은 Master Node 에서 실행되는 다양한 서비스의 다양한 도구 모음이며, Worker Nodes 를 제어하는 컨트롤 센터같은 거라고 생각하자. 우리가 Kube 를 사용할 때, Worker Nodes, Pods 와 직접 상호작용하지 않음(일반적으로 하지 않음) Kube 와 Control Plane 이 우리 대신 Worker Nodes, Pods 와 상호작용 함 Master Node 와 Worker Nodes 가 하나의 Cluster 안에 포함되며 Cluster 내 Nodes 들은 하나의 네트워크를 형성하여 서로 통신이 가능함 EC2 위에 띄운 Master Node 는 Cloud Provider(예를 들어 AWS) 의 API 에 다음과 같은 명령을 보내 Cluster 를 구축함 “내가 지금부터 너의 서비스들을 이용하여 Kube 를 실행할 Cluster 를 만들꺼야. Worker Nodes 만들 EC2 3대를 생성하고, 로드 밸런싱을 위한 로드 밸런서, … 등을 실행해 줘” 그리고 Master Node 에서 Kube 와 Kube 툴을 실행하고 AWS 로부터 받은 리소스(EC2, 로드 밸런서 등)를 이용하여 Pods 를 띄우는 등의 작업을 진행함 Kube 사용자가 (Cloud Provider 도움 없이) Kube 를 사용하기 위해 해야 할 일들이 있음 Kube 는 infrastructure 에 대해 전혀 신경쓰지 않기 때문에 사용자가 infra 를 미리 구축해주어야 함 Nodes 로 사용될 머신들 (AWS 의 경우 EC2) 을 준비해야하며 준비된 모든 Nodes 에 Kube (API Server, kubelet 등의 Kube services, softwares) 를 설치해야 함 필요하다면, cloud provider 로부터 얻을 수 있는 로드 밸런서 등의 리소스를 미리 준비 사용자가 위와 같은 infra 리소스들(Nodes, 로드 밸런서 등)을 준비해두면 Kube 는 이 리소스들을 알아서 운용함 Worker Node 에 대해 자세히 알아보자. Worker Node 는 (위에서 설명한 것처럼) 하나의 머신이며 Master Node 에 의해 관리됨 Worker Node 안에서 하나 이상의 Pods 가 있고 이 Pods 또한 Master Node 에 의해 관리됨 (따라서 Worker Node 가 Pod 를 삭제할 수 없음) Worker Node 에 꼭 설치되어 있어야하는 것들은 다음과 같음 – Docker : Pods 내 Container 실행에 사용됨 – kubelet : Master Node 와 통신할 때 사용됨 – kube-proxy : (Pods 내 Container 에 의해) 해당 node 로 들어오고 나가는 네트워크 트래픽을 처리할 때 사용됨 AWS 를 사용하는 경우, 위에서 언급한 필요한 머신(instance) 및 소프트웨어들을 AWS 가 알아서 설치해준다고 함 Pods 는 하나 이상의 Containers 를 실행하고 있음 일반적으로 pod 하나에 Container 하나 실행 Pods 는 Container 외에 Volumes 같은 리소스도 실행 가능(..!) 이 Volume 은 Container 가 사용 가능한 저장소임 Pods 는 Containers(와 Volumes) 를 묶는 논리적인 단위 같은 거라고 이해하면 편할 듯 kubelet 은 Worker Node 에 존재하며, 다음과 같이 노드 및 파드 운영에 큰 역할을 담당하고 있음 – 파드 관리 : Master Node 로부터 할당된 파드를 Worker Node 에 배치하고 실행 파드 상태 주기적으로 모니터링하고 문제 발생시 다시 시작 – 컨테이너 실행 : 파드에 정의된 Container 를 실행하고 관리 Container 시작/중지 및 리소스 할당 – 리소스 모니터링 및 보고 : Worker Node 의 리소스 사용량 모니터링하여 클러스터 상태 파악 모니터링 정보는 Master 에 보고되고, 클러스터 스케줄링할 때 사용됨 – 상태 모니터링 및 보고 : Worker Node 및 파드 상태를 Master 에 보고함 이를 통해 Master 는 전체 클러스터 상태 파악이 가능 – Worker Node 자동 복구 : Worker Node 가 비정상적으로 종료되면 자동으로 복구 시도 이를 통해 Worker Node 의 가용성을 유지하고 안정성을 보장 참고 : https://velog.io/@gun_123/Kubernetes-Kubelet#:~:text=%EC%9D%84%20%EC%A7%80%EC%9B%90%ED%95%A9%EB%8B%88%EB%8B%A4.-,1.%20Kubelet%EC%9D%B4%EB%9E%80%20%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80%EC%9A%94%3F,%EB%A5%BC%20%EC%8B%A4%ED%96%89%20%EB%B0%8F%20%EA%B4%80%EB%A6%AC%ED%95%A9%EB%8B%88%EB%8B%A4. Master Node 에 대해 자세히 알아보자. Master Node 는 (위에서 설명한 것처럼) 하나의 머신이며 Worker Node 를 관리함 Master Node 에 꼭 설치되어 있어야하는 것들은 다음과 같음 – API Server : Worker Node 의 kubelet 과 통신할 때 사용 – Scheduler : Pods 들을 관찰하고, Pod 를 생성할 Worker Node 를 선택하는 일을 담당 (Pod 다운되었거나, 비정상적이거나, 스케일링으로 새로 Pod 를 생성하는 경우) Scheduler 가 API Server 에게 “Pods 2 대 새로 생성해” 같은 요청 전달하면 API Server 가 그걸 받고 실제 작업을 하나 봄 – Kube-Controller-Manager : Worker Node 전체를 감시하고 제어, Pods 가 의도된 수만큼 떠있는지 확인하는 역할 그래서 API Server, Scheduler 와 긴밀하게 연동된다고 함 – Cloud-Controller-Manager : Cloud-Controller-Manager 는 Cloud Provider 에게 무슨 일을 해야하는지 알려줌 Cloud Provider 에 의해 달라진다고 하는데 구체적으로 뭐가 다른지는 아직 모르겠음 Pods 를 묶는 논리적인 그룹을 Service 라고 함 (위에서 언급된) Poxy 와 연관이 있음 Service 는 특정 Pod 를 외부 세계에 노출하여 특정 IP 혹은 Domain 으로 특정 Pod 에 연결할 수 있도록 하는 용어임…(???) 그럼 Pod 끼리 (Service 에 의해 제공된) IP 로 통신한다는 말이 되나? Kube 사용자는 kubectl 을 통해 사용자가 원하는 명령을 kube(정확히는 Master Node) 에 대신 전달하도록 할 수 있음 kubectl 는, 새로운 deployment 생성, deployment 삭제, 변경 같은 명령을 kube Cluster 에 보내는 데 사용되는 도구임 minikube 를 통해 local 컴퓨터에 kube 를 설치해서 테스트베드로 사용할 수 있음 minikube 를 통해 kube 가 구체적으로 어떻게 동작하는지 알아보자 kube 는 몇 가지 Objects 들이 제 역할을 함으로써 동작함 여기서 Objects 는 언어의 객체 이런 게 아니라, kube 의 핵심 파트 한 부분 부분을 의미한다고 보면 됨 kube 의 Objects 는 Pods, Services, Deployments, Volume….. 등임 사용자가 명령적 방식 혹은 선언적 방식 두 방식 중 하나를 통해 kube 에 “이러저러한 Objects 를 사용하는 이 코드를 실행시켜줘” 라고 명령함 그럼 kube 는 그 코드를 그대로 실행하고, 사용자가 원하는 것이 실행됨 Pod object 를 알아보자 Pod 는 kube 에 의해 상호 작용하는 가장 작은 유닛. kube 는 pods 와 pods 내 containers 를 관리함 Pods 는 기본적으로 cluster 내부 IP 를 갖고 있음 (사용자가 ip 수정 가능) Pods 내에 여러 containers 가 있는 경우, 이 containers 은 localhost 를 통해 서로 통신한다고 함 사용자가 코드를 통해 kube 에게 Pods 를 생성하라고 명령을 보내면 kube 는 worker nodes 중 하나를 선택하고 그 위에 pods 를 생성 및 실행함 pods 는 container 처럼 일시적으로 올라가는 것임. pods 가 내려가면 그 동안의 모든 데이터가 손실됨 pods 에 이상이 생기면, kube 가 알아서 pods 를 재실행함 deployment object 를 알아보자 deployment 는 사용자의 desired state 를 담고 있는, 일종의 명령서같은 것 deployment 는 kube 로 작업할 때 만지게 될 주요 object 중 하나임. 왜냐하면 deployment 를 통해 kube 에 다양한 실행 명령을 내릴 수 있기 때문 deployment 를 통해 하나 이상의 pods 를 제어할 수 있고, 내부적으로 컨트롤러 객체를 생성할 수 있음 사용자는 deployment 를 통해 pods 를 띄우거나 함 (사용자가 deployment 없이 pods 를 직접 띄우지는 않는 듯) deployment 를 일시중지 하거나, 삭제하거나, 롤백할 수 있음 만약 새로 배포한 deployment에 이상이 생겼다면 바로 롤백해서 그 전 deployment 상태로 되돌릴 수 있다는 말임 이런 기능을 시스템적으로 제공함 deployment 는 다이나믹하게 그리고 자동으로 scaling 이 가능함 사용자는 deployment 에 n 개의 pods 를 띄워달라고 설정할 수 있고 그에 맞게 scaling 이 됨 혹은 traffic 이 많아지면 pods 개수를 늘리는 등의 scaling 설정도 가능함 service object 를 알아보자 Service 는 Pods 혹은 Pods 내의 Container 에 접근하기 위해 필요한 object 임 Service 는 Pods 의 ip 를 노출시켜, 다른 Pods 가 ip 가 노출된 Pods 에 접근 가능하도록 만들거나 혹은 외부에서 ip 가 노출된 Pods 에 접근 가능하도록 만듦 각 Pods 는 기본적으로 cluster 내부 IP 를 갖고있는데, 외부에서 이 ip 를 통해 Pods 에 접근이 불가능함 또한 Pods 의 내부 ip 는 Pods 가 교체 될 때마다 변경됨 이런 특징들은 Pods 를 사용할 때 꾸준히 문제가 되는데, Service 가 이를 해결해줄 수 있음 Service 는 Pods 를 그룹화하고 고정된 공유 IP 주소를 제공함 하나의 Service 내에 여러 pods 가 포함되어있고, Service 는 이 pods 에 접근 가능한 하나의 고정된 ip 를 제공하는 것임. service 가 제공하는 ip 는 다른 Pods 혹은 외부에서 접근 가능함 흠.. service 가 제공하는 ip 가 하나뿐이라면, 내부에 각 pods 는 어떻게 구분해서 접근 가능한거지? port number 로 구분하나..? kube 에서 객체들을 띄우기 위한 방법을 두 가지 제공함 명령적 접근방식 vs 선언적 접근방식 명령적 접근 방식은 deployment, service 등을 띄우는 명령어를 직접 입력하여 하나씩 띄우는 것 마치 docker run 을 여러번 하여 containers 를 띄우는 것과 같음 선언적 접근 방식은 띄우고 싶은 객체들의 정보를 입력해 둔 config 파일(yaml) 을 만들고 이 yaml 을 이용하여 한 번에 띄우는 것 마치 docker-compose 를 통해 한 번에 여러 container 를 띄우는 것과 같음 예를 들어 다음과 같이 config 파일인 yaml 파일을 만들 수 있음 apiVersion: apps/v1 kind: Deployment metadata: name: first-app spec: selector: matchLabels: app: first-dummy replicas: 3 template: metadata: labels: app: first-dummy spec: containers: – name: first-node image: “first-app” config 파일을 이용하려면 아래처럼 kubectl apply 라는 명령어 사용 kubectl apply -f first-app.yaml kube 는 yaml 에 설정된 것을 유지하기 위해 노력함 예를 들어 pods 가 하나 죽어서 live pods 가 3개에서 2개가 되었다면 yaml 의 상태(pods 의 replicas 는 3)를 맞추기 위해, 하나를 새로 띄워서 3개를 맞춤 사용자가 yaml 을 업데이트하면, kube 는 그 업데이트 된 사항을 확인하고 그대로 환경을 구성함 Deployment 를 생성하는 yaml 파일을 만들어봄. 공식 문서를 계속 참고 및 확인할 것 https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.26/#deployment-v1-apps apiVersion: 현재 kube 에 맞는 apiVersion 을 찾아서 넣음 선언적 접근 방식을 사용한다면 반드시 넣어야 함 “kubenetes deployment apiversion” 등으로 검색해서 나온 최신 버전 yaml 샘플 등에서 발췌하여 넣으면 됨 예를 들면 아래 스샷과 같이 “apps/v1” kind: Deployment Kube 에서 생성하고 싶은 Object 를 넣음 예를 들어 Deployment, Service, Job 등 metadata : 생성하는 Object 의 이름 등의 정보를 넣음 예를 들어 kind 에 Deployment 가 추가되었다면, 아래처럼 Deployment 의 이름을 first-app 으로 명명 name: first-app spec : 생성하는 Object 의 사양(spec) 정보를 넣음 예를 들어 위 kind 에 Deployment 가 추가되었다면, (아래처럼) 구성하고 싶은 Deployment 의 사양을 입력 replicas: 3 pods 의 개수를 지정. default 는 1이며 (처음에 pod 를 띄우고 싶지 않다면) 0으로도 지정 가능 selector: deployment 가 계속 관리해야 할 pod 의 라벨을 넣음. pod 의 라벨은 아래 다시 설명됨 matchLabels: app: first-dummy deploy: second-dummy tier: third-dummy 여기서 pod 의 라벨이 3개 추가되었음. 이 말 뜻은, 3개 라벨이 충족하지 않거나, 다른 라벨을 갖는 pod 는 해당 deployment 에 의해 관리되지 않는다는 말임. deployment 에 속한 pods 를 deployment 에게 알려준다고 할 수 있음… template: pod 에서 동작할 Container Image 를 정의하는 부분 위 kind 가 Deployment 이기 때문에, 여기서의 template 은 PodTemplateSpec 이 되며 [문서] PodTemplateSpec 에는 metadata 와 spec 두 가지를 추가할 수 있음 [문서] (kind: Pod) 파드Object 만들기 위해 추가. 위 kind 가 Deployment 라면 여기 kind 는 자동으로 Pod 가 되어 여기 kind (kind: Pod) 생략 가능 metadata: pod 는 kube 세계의 새로운 Object 이기 때문에 metadata 를 한 번 더 중첩시켜 넣어줌 labels: deployment 에 의해 관리될 pod 의 라벨 설정. 사용자가 원하는 labels 을 여럿 추가할 수 있음 app: first-dummy deploy: second-dummy tier: third-dummy spec: Pod 의 사양을 정의. 위 Spec 은 Deployment 의 사양이고, 여기 Spec 은 Pod 의 사양 containers: Pod 안에 올라갈 Container 리스트를 정의. 예를 들어 두 가지 Container 를 띄운다면 – name: first-node image: mydockerhub/first-app – name: second-node image: mydockerhub/second-app:4 이렇게 만들어진 yaml 파일 이름이 mykubecluster.yaml 이라고 하자 이 yaml 을 기반으로 kube 에 클러스터를 띄우려면 kubectl apply 명령어 사용 kubectl apply -f=mykubecluster.yaml deployment 를 실행한 이후에, 아래 명령어들을 이용하여 Objects 가 잘 떴는지 확인 kubectl get deployments kubectl get pods 위 deployment 를 위한 yaml 외에, service 를 위한 yaml 을 추가해봄 만들어지는 yaml 파일 이름은 사용자가 정하면 됨. 이를테면 myservice.yaml 등 [service v1 core Documentation] apiVersion: v1 kind: Service metadata: name: backend spec: selector: app: first-dummy deploy: second-dummy tier: third-dummy port: – protocol: ‘TCP’ port: 80 #외부 (로 노출되는) 포트 targetPort: 8080 #(외부 포트와 연결되는) 내부 포트 – protocol: ‘TCP’ port: 443 targetPort: 443 type: ClusterIP service 의 selector 는 deployment 의 selector 와 마찬가지로, 해당 service 에게 제어되거나, 연결되어야 하는 다른 리소스를 식별하는 데 사용함 deployment 에 의해 생성된 pods 를 service 의 selector 에 추가하여 설정 가능 만약 두 개의 deployments A, B 가 있고 A deployment 는 x:x, y:y 라벨을 갖는 pods 를 갖고 B deployment 는 x:x 라벨만 갖는 pods 를 갖는다고 하자 Service select 에 x:x 만 설정해두면 A deployment 의 pod 와 B deployment 의 pod 모두를 대상으로 설정하여 해당 Service 의 그룹에 포함시켜 Service 에 의해 제어되도록 할 수 있음 참고로 Service 의 selector 는 matchLabels 밖에 없음 이렇게 Service 의 selector 로 pods 그룹을 설정한다고 해도 pods 그룹만 알 뿐이지 구체적으로 어떤 pods 가 (Service 에 의한 port 에) 노출되어야 하는지는 아직 모름 port 를 통해 pods 가 외부에서 오는 어떤 port 를 받을 수 있게 할건지(port: 80) 외부에서 오는 요청이 내부 시스템의 어떤 port 로 연결되게 할 건지(targetPort: 8080) 설정할 수 있음 type 에는 여러 값을 넣을 수 있음 – ClusterIP : default. 내부적으로 노출된 IP. 클러스터 내부에서만 접근 가능하며, 클러스터 내부 pod 들끼리 통신 가능 해당 타입의 Service 에 속한 pod 에 들어오는 요청을 자동으로 모든 pod 로 분산 – NodePort : 기본적으로 실행되는 worker node 의 ip 와 port 에 노출 – LoadBalancer : 외부 세계에서 pod 로 접근을 원하는 경우 사용. 가장 일반적으로 사용됨 외부에서 사용 가능한 IP 주소를 생성하고 실행되는 (pod 가 어떤 노드에 떠 있느냐에 관계없이) 모든 pod 에 들어오는 요청을 자동으로 분산하고 생성된 고정 IP주소는 Pod 가 실행되는 노드와 독립적임 이렇게 만들어진 myservice.yaml 을 kube 에 올릴때는 아래 명령어 사용 kubectl apply -f myservice.yaml service 를 실행한 이후에, 아래 명령어를 이용하여 service 가 잘 떴는지 확인 kubectl get services kube 에 올라간 deployments 나 services 의 설정을 업데이트하고 싶다면 yaml 파일을 업데이트하고 다시 실행(kubectl apply -f …)하면 됨 그러면 업데이트 된 내용이 kube 클러스터에 자동으로 반영됨 kube 에 올라간 리소스(deployments, services…) 를 삭제하고 싶을 때는 delete 명령어에 삭제할 리소스 이름(metadata.name)을 넣어서 사용 kubectl delete deployment first-app kubectl delete service backend 혹은 아래처럼 yaml 파일 이름 자체를 넣어, yaml 에서 생성한 모든 리소스들 삭제 가능 kubectl delete -f=mykubecluster.yaml kubectl delete -f=myservice.yaml kubectl delete -f=mykubecluster.yaml, myservice.yaml kubectl delete -f=mykubecluster.yaml -f=myservice.yaml 위에 예제에선 두 개의 yaml 을 사용하여 리소스를 띄웠고 두 yaml 의 리소스들이 서로 협력하여 일 하도록 만들었음 어짜피 같이 일 하게 될꺼라면 하나의 yaml 에 넣어도 되지 않을까? 가능함. 두 개의 yaml 내용을 하나의 yaml 에 합치려면 아래와 같이 진행하면 됨 < myservice.yaml > apiVersion: v1 kind: Service metadata: name: backend …. < mykubecluster.yaml > apiVersion: apps/v1 kind: Deployment metadata: name: first-app …. < total.yaml > apiVersion: v1 kind: Service metadata: name: backend …. — apiVersion: apps/v1 kind: Deployment metadata: name: first-app …. 두 yaml 내용 사이에 “—” 를 꼭 넣어줘야 함 “—” 는 yaml 에서 Object 를 구분하는 기호라고 함 위와 같이, 여러 yaml 을 묶을 때는 Service Object 를 위한 yaml 을 먼저 배치하는 게 좋다고 함 리소스는 위에서 아래로 내려오면서 차례대로 생성되어 Service 가 먼저 생성됨 Service 는 이후 생성되는 pods 등의 라벨을 보면서, Service 에 지정된 라벨이 생성되는지 확인함 지정된 라벨의 pods 가 생성되면 동적으로 Service 에 추가됨 위 예제의 deployments 설정 yaml 에서 selector 로 matchLabels 을 사용했는데 matchLabels 말고 matchExpressions 를 사용할 수 있음 https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.26/#labelselector-v1-meta https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.26/#labelselectorrequirement-v1-meta 예를 들어 아래와 같은 matchLabels selector 를 matchExpressions selector 로 바꾼다고 하자 < matchLabels selector > selector: matchLables: app: second-app tier: backend < matchExpressions selector > selector: matchExpressions: – {key: app, operator: In, values: [first-app, second-app]} key 는 Label 의 key 값 values 는 Label 의 value 값 operator 에 In, NotIn, Exists, DoesNotExist 등이 들어갈 수 있음 위에서 사용된 In 은 values 리스트에 포함되어있으면 match 됨 예를 들어 어떤 pod 의 Label 이 app:second-app 이라면, 위 matchExpressions selector 에 의해 match 됨 만약 NotIn 을 선택했다면, app:second-app Label 을 갖는 pods 는 match 에서 제외될 것임 kube 에서 실행된 Container 가 우리 의도에 따라 정상적으로 실행 중인지 검사하는 방법을 직접 정의할 수 있음 예를 들어 위 예제에서 deployment yaml 의 pods spec.containers 를 보자. apiVersion: apps/v1 kind: Deployment metadata: name: first-app spec: selector: matchLabels: app: first-dummy replicas: 3 template: metadata: labels: app: first-dummy spec: containers: – name: first-node image: “first-app” livenessProbe: httpGet: path: / port: 8080 periodSeconds: 10 initialDelaySeconds: 5 livenessProbe : Container 가 구동된 이후 잘 실행중인지 검사하기 위해 설정하는 값들 httpGet : http 의 get 요청이 pods 에서 실행중인 application 으로 전달되어야 함을 의미 periodSeconds : 작업을 수행 빈도(초단위). 10을 넣으면 10초 initialDelaySeconds : kube 가 처음으로 상태를 확인할 때까지 기다려야 하는 시간(초단위) 5를 넣으면 5초 kube 자체적으로 Container 가 죽으면 다시 띄워주긴 하지만 Container 내부 app 이 이상한 방향으로 동작하거나 kube 가 알아차리지 못하는 방식으로 죽어버리는 상황을 대비하기 위해 사용자가 직접 “/:8080 으로 10초간 ping 을 보내서 제대로 동작하는지 확인해봐” 라고 검사 설정을 해둘 수 있음