원글 페이지 : 바로가기
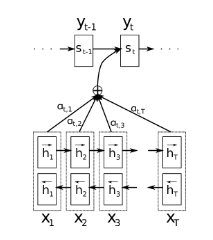
출처 : https://kyull-it.tistory.com/212 출처 : https://brunch.co.kr/@jean/5 이전 포스트에서 다룬 Seq2Seq의 개념을 바탕으로 Attention Mechanism에 대해 학습해본다. Attention Mechanism과 관련된 논문 “Neural Machine Translation by Jointly Learning to Align and Translate”를 리뷰한다. 1. Attention Mechanism 2. 논문 리뷰 1. Attention Mechanism 1) Attention Mechanism 등장 배경 – Seq2Seq 방식은 고정된 크기의 벡터에 문장 속의 모든 정보를 인코딩하기 때문에 정보 손실이 발생한다. – Seq2Seq까지의 encoder-decoder 모델은 다른 길이의 input에 대해 고정된 길이의 context vector를 출력 – input의 모든 정보를 한정된 길이의 벡터로 압축하기 때문에 문장의 길이가 길어지면 context vector에서 정보의 손실이 발생 ➡️ Attention Mechanism = context vector가 input의 모든 정보를 압축해서 담는 것이 아니라 input 내에서 target word와 관련된 일부분에 집중하여 중요한 정보만 들고오는 것 = 고정된 길이의 context vector를 사용하지 않고 target word를 생성하는 매 시점마다 동적으로 context vector를 계산 = target word를 생성하는 매 시점마다 target에 대한 모든 input words의 가중치 계산 target word 생성에 어떤 input words가 중요한지 계산 ==> target word와 관련 있는 input words에 더 attention을 주어 예측한다! Attention Mechanism 논문의 의의 – input과 모든 다른 단어들 간의 관계를 고려함으로써 Long Term Dependency 문제를 극복 (monotonic alignment 해소) – 신경망 모델에 어느정도의 explainability를 부여 (각 단어가 다른 단어와 어떻게 관련이 있는지 시각화할 수 있음) 2) Attention Mechanism의 구조 Query(Q) : s_i, i 시점에서 decoder RNN의 hidden state Key(K), Value(V) : h_j, 각 시점 j에서 encoder RNN의 hidden state 1단계 : Attention Score e_ij 출처 : https://velog.io/@sjinu/%EA%B0%9C%EB%85%90%EC%A0%95%EB%A6%AC-Attention-Mechanism#3-%EB%8B%B7-%ED%94%84%EB%A1%9C%EB%8D%95%ED%8A%B8-%EC%96%B4%ED%85%90%EC%85%98dot-product-attention – Attention Score = Q(s_i)와 K(h_j) 사이 유사도 값 – i 시점 decoder의 hidden state Q와 각각의 j 시점에서 encoder hidden state K 간 유사도를 계산 – s_i와 h_j 사이 attention score (annotation score) e_ij 계산 – encoder의 j 위치에서의 정보가 decoder의 i 위치에서의 정보와 얼마나 연관되어 있는지 의미 2단계 : Attention Distribution 출처 : https://ctkim.tistory.com/entry/Attention-Mechanism – Attention Distribution = Q(s_i)에 대한 encoder hidden state K(h_j) 의 가중치 분포(확률 분포) – Softmax 함수를 이용해 score e_ij를 각각 0~1의 값을 가지고 전체 합이 1이 되는 가중치 분포로 변환 – e_ij를 정규화하여 attention weight (annotation weight) α_ij 계산 3단계 : Attention Value – Attention Value = decoder state i에서 context vector – 가중치 α_ij와 encoder hidden state V 값을 곱해 최종 attention 값을 계산 – 가중치 α_ij와 h_j를 곱해 최종 context vector c_i 계산 – c_i는 고정 길이 벡터가 아니라 decoder state i마다 동적으로 계산됨 4단계 : Attention value와 decoder의 hidden state 연결 – c_i와 s_i를 연결하여 v_i 생성 – v_i는 decoder hidden state의 정보와 encoder hidden state의 정보를 모두 가지고 있는 벡터 5단계 : 신경망 연산으로 최종 target word 생성 출처 : https://aiheroes.ai/community/80 – v_i에 활성화 함수, softmax 함수를 거쳐 최종 조건부 확률 계산 – input x가 주어졌을때 output y_i의 조건부 확률 계산 ➡️ Attention Mechanism 전체 과정 → Attention Score e_ij = s_i와 h_j 사이 유사도 encoder state j의 정보가 decoder state i와 얼마나 연관되어 있는가 → attention weight α_ij = e_ij에 softmax 함수 적용 Attention Distribution = 가중치 α_ij 값의 분포 encoder state j가 decoder state i와 연관되어 있을수록 높은 가중치 부여 → Attention Value = decoder state i에서 context vector c_i = 가중치 α_ij와 h_j의 곱 context vector는 고정 길이가 아닌 decoder state i마다 동적으로 계산 → c_i와 s_i를 연결하여 v_i 생성 → 신경망 연산으로 최종 target word 예측 출처 : https://ctkim.tistory.com/entry/Attention-Mechanism, 사진 위 주석은 직접 작성한 내용 3) Attention Function – target word에 대한 각 input words의 attention score를 계산하는 함수 – 어떤 attention function을 사용하느냐에 따라 다양한 attention 종류가 존재 출처 : https://velog.io/@sjinu/%EA%B0%9C%EB%85%90%EC%A0%95%EB%A6%AC-Attention-Mechanism#3-%EB%8B%B7-%ED%94%84%EB%A1%9C%EB%8D%95%ED%8A%B8-%EC%96%B4%ED%85%90%EC%85%98dot-product-attention 2. 논문 리뷰 논문명 : Neural Machine Translation by Jointly Learning to Align and Translate 저자명 : Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio https://arxiv.org/abs/1409.0473 Neural Machine Translation by Jointly Learning to Align and Translate Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra arxiv.org ✏️ 논문 내용 정리 – Attention 모델 고안 배경 : 기존의 encoder–decoder 구조의 NMT 모델은 source sentence를 고정된 길이의 벡터로 인코딩하기 때문에 필요한 모든 정보를 고정된 길이로 압축해야한다는 한계가 있음 – Attention 모델과 이전 모델의 차이점 ” encoder–decoder model which learns to align and translate jointly ” : encoder–decoder 구조에 어텐션 메커니즘을 적용해 정렬과 번역을 같이 학습 – Attention 매커니즘 : 모델이 입력 데이터에서 중요한 부분에 집중하도록 가중치를 부여하는 방법 alignment를 학습해 ouput을 예측할 때 input에서 중요한 일부 위치만 고려 * alignment = input의 특정 위치와 output의 특정 위치를 연결시키는 방법 – Attention 모델의 구조 ① Attention 매커니즘을 도입한 Decoder : 번역시 source sentence에서 output과 가장 관련있는 input 영역을 검색 ● a( ) : alignment model ● α_ij : annotation weight, y_i에 대한 x_j의 attention ● α_ij를 이용해 y_i를 생성하기 위해 더 attention을 주어 사용할 x_j 위치를 파악 ② Bidirectional RNN을 사용한 Encoder : encoder의 hidden state(annotation)를 양방향으로 구성함으로써 x_j에 대한 정보에 x_j의 preceding words와 following words의 정보를 모두 반영 – 논문에서 보인 모델 특성 ① English-to-French translation 작업에서 sota와 필적할 수준의 번역 성능 달성 ② soft-alignment를 사용함으로써 문맥을 고려하고 인간의 직관에 잘 맞는 번역 ③ 특히 긴 문장을 번역하는 능력이 기존 모델에 비해 훨씬 뛰어남 ▶ 0. Abstract – 이전까지 고안된 encoder–decoder 구조의 NMT 모델은 source sentence를 고정 길이 벡터로 인코딩한다는 점에서 아키텍처 성능을 향상시키는데 한계가 있음 – target words 생성 시 관련성이 높은 source sentence의 일부분을 자동으로 검색하는 방식으로 확장한 새로운 아키텍처를 제안 – 제안된 모델은 English-to-French translation 작업에서 sota 시스템과 필적할 수준의 번역 성능을 달성 – 또한 모델이 학습한 입력과 출력 간 soft-alignment는 직관과 잘 일치함 ▶ 1. Introduction 1) 기존 encoder–decoder NMT 모델의 한계 – encoder neural network는 source sentence를 읽어 고정된 길이의 벡터로 인코딩하고, decoder neural network는 인코딩된 벡터에서 번역 결과를 출력함 – encoder와 decoder는 주어진 source sentence에 대한 올바른 번역의 조건부 확률을 최대화하도록 훈련됨 – source sentence에서 필요한 모든 정보를 고정된 길이 벡터로 압축해야한다는 문제 (bottleneck 문제) – 특히 train에 사용한 문장보다 더 긴 문장에 대해서 encoder–decoder 구조 모델의 성능이 크게 저하됨 2) 새로운 모델 고안 “Attention mechanism을 이용해 정렬과 번역을 같이 학습하는 encoder-decoder 모델” ○ decoder에서 번역 결과를 생성할 때마다, source sentence에서 현재 번역하려는 부분과 가장 관련있는 정보가 있는 영역을 검색 ○ 관련성이 큰 영역에서 인코딩 된 context vector + decoder가 이미 생성한 이전 번역 결과에 기반하여 다음 단어를 예측 – 입력 문장 전체를 단일 고정 길이 벡터로 인코딩하는 것이 아닌 – 입력 문장을 벡터 sequence로 인코딩하고, 번역을 디코딩하는 동안 이 sequence의 하위 집합을 참조하여 선택하는 방식 – source sentence의 모든 정보를 고정된 길이 벡터로 줄여야하는 문제를 해결함으로써 모델이 긴 문장에도 더 잘 대처할 수 있게 됨 * Alignment 정렬 : 모델이 input sequence와 output sequence의 특정 위치를 연결시키는 방법 alignment는 Attention 모델이 input sequence의 어떤 부분을 output의 특정 부분을 예측하는데 중요하게 사용할지 결정하는 역할을 하며, 모델의 학습 과정에서 자동으로 학습됨 ▶ 2. Background: Neural Machine Translation 기존의 NMT에서 모델은 – source sentence x를 인코딩하고, target sentence y로 디코딩하는 방식 – (x, y) sentence pairs 데이터를 이용해 p(y|x)를 최대화하도록 모델 학습 – 번역은 새롭게 주어진 x에 대하여 p(y|x)이 최대인 y를 생성하는 형태 – Sutskever et al. (2014) 논문에서 다룬 RNN(LSTM)을 encoder, decoder로 사용한 NMT 모델은 영어-프랑스어 번역 작업에서 기존 구문 기반 MT의 sota에 근접한 성능을 보임 ▶ 2.1 RNN Encorder-Decoder – encoder : input sentence를 읽고, hidden states를 거쳐, context vector c를 출력 – decoder : context vector c와 이전 번역 단어들로 다음 단어를 예측 ▶ 3. Learning to Align and Translate 새로운 NMT 모델을 제시 encoder : bidirectional RNN decoder : 번역을 디코딩하는 동안 source sentence에서 검색을 수행 ▶ 3.1. Decoder: General Description (x_1, x_2, …, x_T) : source sentence y_t : t-th target word s_i : decoder RNN의 hidden state at time i h_j : annotation at time j, encoder RNN의 hidden state at time j α_ij : annotation weight, y_i에 대한 x_j의 attention ① a( ) : alignment model (정렬 모델) e_ij : s_(i-1)와 h_j에 대한 alignment model score – encoder의 j 위치에서의 정보가 decoder의 i 위치에서의 정보와 얼마나 연관되어 있는지 점수화 – output의 i 위치와 input의 j 위치 주변이 얼마나 매칭되는지 계산 – decoder의 (i−1)에서 hidden state s_(t−1)과 encoder j에서 hidden state h_j를 이용하여 계산 – a는 피드포워드 신경망으로 역전파를 이용해 모델의 다른 모든 구성 요소와 함께 훈련됨 ② α_ij : annotation weight, y_i에 대한 x_j의 attention – y_i에 대한 x_j의 영향력을 의미 – y_i가 x_j에 얼마나 연관이 있는지 나타내는 나타냄 – y_i가 x_j로부터 번역되거나 정렬되었을 확률 – decoder가 y_i를 번역할 때 source sentence에서 어떤 위치의 단어에 더 attention을 줄지 결정하는 weight로 사용 – alignment model에서 구한 score e_ij를 이용하여 계산 ③ c_i : distinct context vector – attention을 반영한 context vector – y_i에 대한 x_j의 영향력인 weight α_ij를 반영하여 source sentence에서 y_i와 관련된 부분에 더 집중하여 계산한 context vector – encoder의 j에서 hidden state h_j에 대해 가중치 α_ij를 곱해서 계산 ④ 조건부 확률 – 2에서 다룬 이전 encoder-decoder 모델에서와 달리 context vector로 고정된 c가 아닌 attention이 적용된 c_i를 사용하여 계산 ➡️ Attention 매커니즘을 도입한 Decoder → h_j와 s_(i-1)를 이용해 y_i에 대한 x_j의 attention α_ij를 구하고 → α_ij를 반영하여 중요한 h_j에 더 가중치를 준 context vector c_i를 계산하고 → c_i를 y_i에 대한 조건부 확률 계산에 사용한다! – decoder는 α_ij를 이용해 y_i를 생성하기 위해 더 attention을 주어 사용할 source sentence 위치를 파악한다! – 생성할 output 단어와 연관성이 높은 input 단어들에 더 집중하여 디코딩한다! – source sentence의 모든 정보를 고정된 길이의 벡터로 인코딩될 필요 없이 h_j sequence에 분산되어 저장된다! – decoder는 선택적으로 source sentence에서 주의를 기울일 일부를 결정하여 h_j sequence에서 정보를 검색한다! ▶ 3.2. Encoder: Bidirectional RNN for Annotating Sequences – bidirectional RNN(BiRNN), 양방향 인코더 구조 – forward RNN와 backward RNN로 구성 forward RNN : input sequence를 처음부터 순차적으로 읽으면서 forward hidden states (h_1→, h _ 2→, ⋯, h _ Tx→)를 생성 backward RNN : input sequence를 뒤에서부터 역방향으로 읽으면서 backward hidden states (h _ 1←, h _ 2←, ⋯, h _ Tx←)를 생성 입력 x_j에 대한 forward hidden state h _ j→ 와 backward hidden state h _ j← 를 연결하여 j-번째 hidden state(annotation) h_j를 생성 – RNN의 hidden state 특성으로 인해 h_j는 입력 단어 x_j의 가까운 위치에 있는 단어들의 정보를 더 많이 보유하게 됨 – annotation이 x_j의 preceding words뿐만 아니라 following words에 대한 정보도 잘 반영할 수 있도록 변형 – h_j를 기반으로 계산되는 context vector c_i도 x_j의 앞과 뒤 정보를 모두 고려 ➡️ Bidirectional RNN을 사용한 Encoder – encoder의 hidden state(annotation)를 양방향으로 구성함으로써 source sentenced의 x_j에 대한 정보가 x_j의 preceding words와 following words를 모두 반영하도록 한다! ▶ 4. Experiment Settings – English-to-French translation 과제로 모델 평가 – RNN Encoder-Decoder 모델과 성능 비교 ▶ 4.1. Dataset – 사용한 WMT ’14 데이터셋은 English-French corpus 데이터셋 – 전체 850만개 단어 중 348만개 단어로 크기를 줄인 후 토큰화 진행 언어별로 가장 빈도 높게 등장하는 3만개 단어만 vocabulary로 사용하고 해당되지 않는 단어는